
| 【💡TL;DR / 文章核心摘要】 robots.txt 是一個必須放置於網站根目錄下的純文字檔案(檔名必須全小寫),用來規範搜尋引擎爬蟲(如 Googlebot)與新興 AI 機器人,哪些網頁可以存取,哪些應避免。 其核心用途包含: – 🚦管理網站流量與檢索預算。 – 🛡️避免非重要頁面被錯誤索引(如隱私頁面、後台、測試環境)。 – 🧠自主管理 AI 爬蟲行為(決定放行或阻擋未經授權的 AI 底層模型訓練抓取)。 |
在執行網站 SEO 優化時,我們常說「索引」是獲得自然流量的先決條件;但在此之前,搜尋引擎的爬蟲(Spider / Crawler)必須先能夠順利且有效率地「檢索(Crawl)」你的網站。這就像是邀請貴賓來參觀你的博物館,你必須先確保大門是敞開的,且館內的動線標示清晰。
然而,隨著網站規模逐漸擴大,或是近期 AI 搜尋引擎(如 ChatGPT、Perplexity、Google AI Overviews)的快速崛起,網站管理員面臨了一個全新的複雜課題:我們不僅要精準引導傳統搜尋引擎來抓取有價值的網頁,更要嚴格防止海量的 AI 爬蟲無限制地消耗伺服器資源,或是未經授權就擅自擷取你的原創內容。
這時候,建立一個正確、嚴謹且符合最新 AI 趨勢的 robots.txt 就顯得至關重要。它不再只是單純的 SEO 基礎建設,更是保護網站資產的第一道防線🛡️。
本文將帶你從零開始釐清 robots.txt 的核心觀念、基礎語法,並深入探討如何在 AEO(Answer Engine Optimization)與 GEO(Generative Engine Optimization)的 AI 時代,制定最適合你網站的爬蟲控制策略。不再苦惱於該不該封鎖 AI,一次搞懂所有的設定細節與實務避坑指南!
robots.txt 是什麼?
簡單來說,robots.txt 是一個純文字檔案(副檔名為 .txt),它就像是網站專屬的「警衛室」或「佈告欄」。
當任何搜尋引擎的爬蟲(如 Googlebot、Bingbot)或 AI 機器人來到你的網站時,它們的第一站一定會先尋找並讀取這個檔案。這個檔案內包含了「網站排除標準(Robots Exclusion Protocol, REP)」,這是一種國際通用的網路禮儀協議,明確告訴爬蟲們:
- 🟢你可以去哪裡(哪些頁面或目錄是開放抓取的,歡迎光臨)
- 🔴你不准去哪裡(哪些機密、重複或無價值的頁面禁止進入,請止步)
- 🗺️我的網站地圖在哪裡(Sitemap 的完整路徑,讓爬蟲能快速掌握全站結構)
【實務上的小提醒】
- robots.txt 必須放置在網站的根目錄(Root Directory)底下。舉例來說,如果你的網域是 https://www.example.com,那麼 robots.txt 的標準網址就必須是 https://www.example.com/robots.txt。如果放在子目錄下(例如 https://www.example.com/blog/robots.txt),爬蟲是找不到也不會理會的。
- robots.txt 是一個公開的檔案。任何人在瀏覽器網址列輸入該路徑,都能看到你的設定規則。因此,絕對不要在 robots.txt 中暴露極度機密的內部網址結構,以免反而成為駭客攻擊的探路地圖。

為什麼網站強烈建議設置 robots.txt?
或許你會問:「我的網站內容都希望被 Google 看到,那我是不是就不需要 robots.txt 了?」
這是一個極度常見的迷思。即使你希望所有內容都被索引,實務上仍「強烈建議」配置 robots.txt,主要基於以下三大 SEO 效益與伺服器資源管理的考量:
1. 最佳化檢索預算(Crawl Budget)
搜尋引擎分配給每個網站的「檢索預算」是有限的。所謂的檢索預算,是指 Googlebot 在一定時間內願意且能夠在你網站上抓取的網址數量。如果你的網站有大量的動態網址、站內搜尋結果頁(如 ?q=keyword)、或是購物車與會員登入頁面,爬蟲可能會將寶貴的時間浪費在這些對 SEO 毫無幫助的頁面上。
情境模擬:想像你開了一家擁有上萬件商品的電商網站,因為顏色、尺寸的排列組合,產生了數十萬個帶有參數的網址。如果沒有 robots.txt,Googlebot 可能每天都在抓取這些無限生成的重複頁面,導致你辛苦撰寫的最新部落格文章或主打新品,遲遲等不到爬蟲來抓取索引。透過 robots.txt 將這些低價值頁面 Disallow,能引導 Googlebot 集中火力抓取真正能帶來流量的文章與產品頁。
2. 保護測試環境與避免重複內容災難
在網站改版、上線前的「測試機(Staging site)」階段,如果沒有透過 robots.txt 封鎖全站,很容易被 Google 提前索引。這會導致正式上線後出現嚴重的「重複內容(Duplicate Content)」問題,因為 Google 會看到兩個完全一模一樣的網站存在於不同的網域,進而互相瓜分排名權重。此外,若使用者不小心透過搜尋引擎進入測試站並進行假消費,後續的客服處理將會是一場災難。後台登入路徑(如 WordPress 的 /wp-admin/)也建議進行阻擋,減少被暴力破解的機率。
3. 減輕伺服器負載與阻擋惡意消耗
除了傳統搜尋引擎,網路上充斥著各種第三方數據抓取工具(如 AhrefsBot, SemrushBot,甚至是一些不知名的價格監控爬蟲)以及現今海量的 AI 訓練爬蟲。如果不加限制,當這些爬蟲為了盡快取得資料而同時湧入時,它們發出的大量 Request 極可能拖垮你的伺服器效能(CPU 與 RAM 滿載),導致真實用戶在瀏覽網站時感到異常緩慢,甚至出現 502/503 錯誤畫面。合理的 robots.txt 設定能有效管控這些非必要的流量。
robots.txt 的基本語法與規則解析
要撰寫 robots.txt,你不需要具備高深的程式能力,只需掌握以下幾個核心指令與符號即可。請注意,robots.txt 的語法是非常嚴謹的,少一個空白或斜線都可能導致規則失效。
robots.txt 四大核心指令
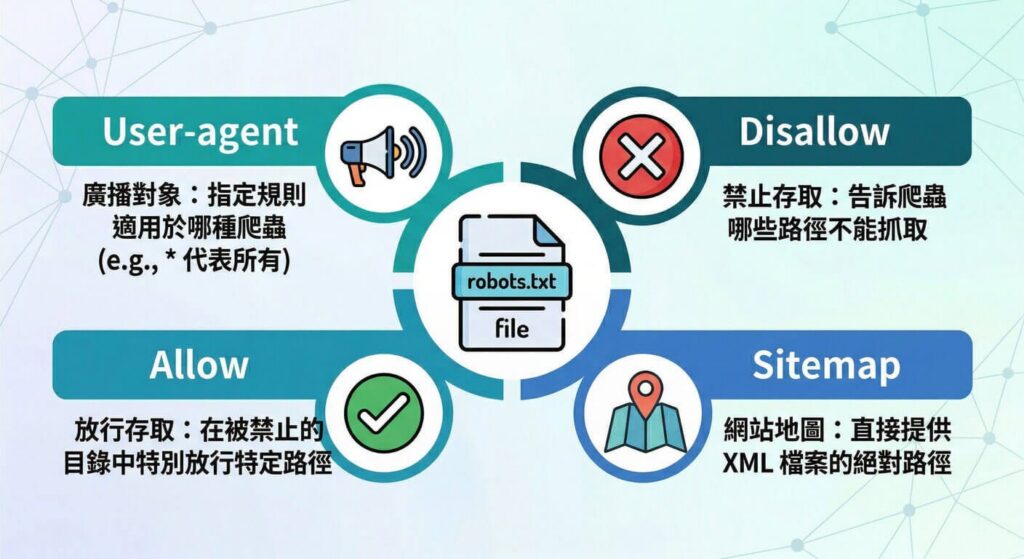
- User-agent(宣告對象):
指定接下來的規則是寫給哪一個特定的爬蟲看。常見的有 Googlebot、Bingbot。若要套用給所有爬蟲,則使用星號 *。通常一個 robots.txt 會將特定爬蟲的規則寫在前面,通用規則 User-agent: * 寫在最後面。 - Disallow(禁止存取):
告訴爬蟲「不要」抓取指定的目錄、頁面或參數。這是一個相對路徑的設定,必須以斜線 / 開頭。 - Allow(允許存取):
告訴爬蟲可以抓取指定路徑。通常會與 Disallow 搭配使用,用來在一個被封鎖的父目錄中,特別「放行」某個子目錄或檔案,這在精細的權限控制中非常實用。 - Sitemap(網站地圖):
直接告訴爬蟲你的 XML 網站地圖放在哪裡,加速網站內容被發現的速度。這裡必須填寫包含 https:// 的絕對路徑。如果你的網站有多個 Sitemap(例如文章一個、產品一個),你可以寫多行 Sitemap 指令,這完全符合規範。
(註:你也可以使用 # 符號來為 robots.txt 加入註解,爬蟲在讀取時會自動忽略 # 後面的所有文字。)
進階應用:萬用字元與特殊符號
- 星號 *(Wildcard / 任意字元):代表任何長度的字串。例如 Disallow: /*.pdf 表示禁止抓取網站內所有的 PDF 檔案。這在阻擋特定副檔名時非常有效。
- 錢號 $(End of URL / 網址結尾):代表網址的絕對結尾。例如 Disallow: /*.php$ 表示禁止抓取所有以 .php 結尾的網址。但如果網址是帶有參數的 .php?id=1,因為結尾不是 p,所以就不受這條規則限制。
AI 時代的 robots.txt:如何面對 AI 爬蟲與 AEO/GEO?
隨著 ChatGPT、Perplexity 的爆發,以及 Google AI Overviews(AI 摘要)的普及,SEO 已經正式進入了 AEO(解答引擎優化)與 GEO(生成式引擎優化)的時代。搜尋行為正在改變,使用者越來越習慣直接向 AI 索取整理好的答案。
許多內容創作者與品牌端開始面臨一個兩難的抉擇:「我到底該不該在 robots.txt 封鎖這些來勢洶洶的 AI 爬蟲?」
要釐清這個觀念,我們必須先將 AI 爬蟲的「行為目的」分為兩大類,並採取完全不同的應對策略:
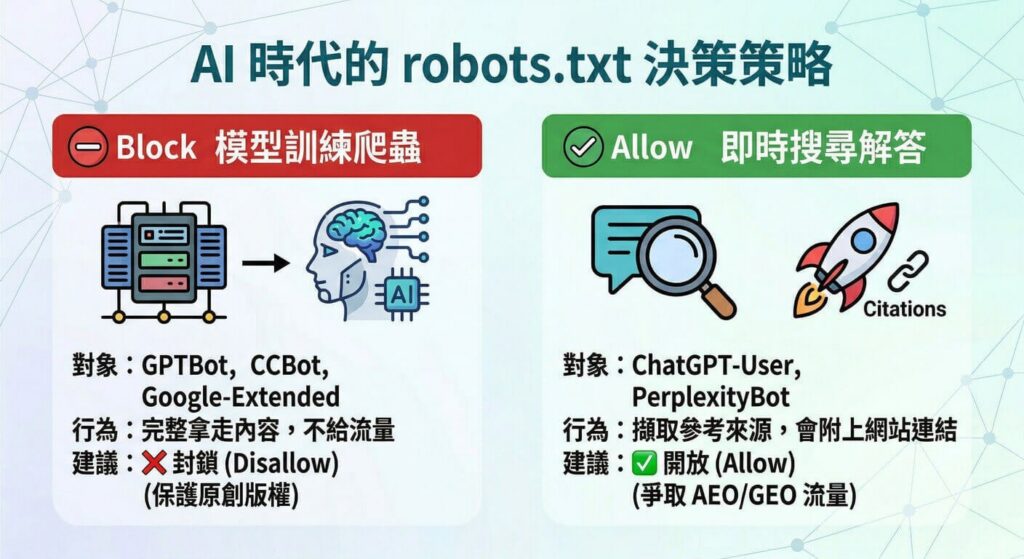
1. 用於「訓練大型語言模型(LLM)」的爬蟲(可評估是否封鎖🚫)
這類爬蟲的目的非常具有侵略性:它們會把你的文章完整爬走,拆解成字詞,丟進巨大的資料庫中訓練下一代的 AI 模型。
- 常見 User-agent:GPTBot (OpenAI), Anthropic-ai (Claude), Google-Extended (Google 訓練用), CCBot (Common Crawl 專案)。
- SEO 顧問解析與建議:當這類爬蟲拿走你的資料後,它們不會在未來的對話中給予你任何反向連結(Backlink),也不會為你的網站帶來一絲一毫的流量。它們只是純粹地吸收你的知識產權。如果你不希望自己的原創心血、獨家商業數據被免費拿去訓練 AI,強烈建議可以在 robots.txt 中將其明確封鎖(Disallow)。
2.用於「即時搜尋與解答(Search & Grounding)」的爬蟲(必須開放✅)
這類爬蟲的行為類似於傳統搜尋引擎。當使用者在 ChatGPT 介面中觸發「搜尋網路」功能,或是 Perplexity 在整理即時答案時,它們會派出這類爬蟲去網路上尋找最新的資訊。它們會擷取你的網頁內容作為參考來源,並且最重要的是:它們會在生成的答案中,明確附上你的網站連結(Citations)。
- 常見 User-agent:ChatGPT-User (OpenAI 網頁搜尋), PerplexityBot (Perplexity 搜尋)。
- SEO 顧問解析與建議:在 GEO 與 AEO 的趨勢下,成為 AI 的「參考來源」是未來獲取高意圖流量的新紅利。強烈建議「不要」封鎖這類爬蟲(保持 Allow)。如果你把它們擋在門外,你將從 AI 搜尋的版圖中徹底消失,白白將曝光機會拱手讓給你的競爭對手。
(註:Google 的 AI Overviews 目前仍是基於標準的 Googlebot 抓取結果來生成摘要答案,因此只要你允許 Googlebot 正常抓取即可,無須為 Google AI Overviews 做額外的特殊放行設定。)
💥 殘酷現實:封鎖了 AI 爬蟲,它們就真的進不來嗎?
雖然前面我們教了如何利用 robots.txt 封鎖 AI 爬蟲,但實務操作上,我們必須帶您認識一個殘酷的現況:
robots.txt 在 AI 爬蟲眼中,只是一套沒有強制力的「君子協定」。
根據國外權威機構 BuzzStream 於2026年4月提出的調查報告『Do News Publishers That Block AI Crawlers Get Cited Less Often by AI?』一文指出,即使許多大型新聞媒體在 robots.txt 中嚴格封鎖了 AI 模型訓練與即時搜尋的爬蟲,但最終在 AI 引擎的回答中,仍有高達 95% 的引用來源來自這些明確拒絕抓取的網站。
為什麼會這樣?因為 AI 抓取技術與繞過限制的方式不斷在進化。有些 AI 會透過不受規範的第三方爬蟲抓取資料,有些則會偽裝成一般使用者的瀏覽器行為(Headless Browser)。這告訴我們一個重要的技術現實:
透過 robots.txt 設定防堵,技術上「可做、應該做」,但絕對不要「過於強求」或以為它能達到 100% 的絕對防禦。
【延伸探討】新興的 llms.txt 是什麼?我需要設定嗎?
在近期探討 AI SEO 與 GEO 的技術社群中,你可能偶爾會聽到一個新名詞:「llms.txt」。這究竟是什麼?它會取代 robots.txt 嗎?
什麼是 llms.txt?
llms.txt 是一個由開發者社群近期發起的「非官方提案」。它的核心構想是:既然 AI 模型(LLM)特別喜歡閱讀 Markdown 格式的乾淨文本,網站管理員是不是能提供一個專屬的 /llms.txt 檔案,裡面放上網站核心內容的 Markdown 摘要,或是專門寫給 AI 看的導覽規則,讓 AI 能更有效率地吸收網站知識?
SEO 顧問的觀點與實務建議:
雖然這個立意十分良好,但身為專業的 SEO 顧問,我們必須為你釐清一個關鍵事實:llms.txt 目前「並非」任何官方認可的通用協定。
截至目前為止,包含 Google、Bing 等傳統搜尋引擎巨頭,以及 OpenAI、Anthropic 等頂尖 AI 實驗室,皆未曾發表過任何官方聲明表示他們會抓取、遵循或優先參考 llms.txt 的內容。
- 沒有實質排名承諾:目前沒有任何數據實證,擁有 llms.txt 能讓你的網站在 AI 摘要(AI Overviews)或 ChatGPT 搜尋中獲得更好的曝光、排名或成為首選引用來源。
- robots.txt 仍是唯一標準:要控制爬蟲的進出與檢索規則,目前全網路唯一公認且具備實質強制力的標準協議(REP),依然只有 robots.txt。
針對 llms.txt,我們建議抱持「了解即可、持續觀望」的態度👀。除非你擁有極度充裕的工程資源,且非常熱衷於進行前沿的技術實驗,否則現階段完全不需要為了這個尚未成氣候的非官方檔案感到焦慮。與其花時間琢磨如何產出 llms.txt,不如把精力投資在撰寫更高品質的原創內容,並確保網站具備清晰的 HTML 語意架構(Semantic HTML),這才是迎戰 AEO 時代最根本的王道。
robots.txt 在不同情境實務操作範例
為了讓大家更好理解,以下列出幾種常見的實務情境與對應的代碼寫法。你可以直接複製並修改成適合自己網域的版本:
範例一:全站開放,僅提交 Sitemap(最常見的內容網站/企業形象網站)
這是最友善、最基礎的設定,允許所有爬蟲暢行無阻地抓取,並指引 Sitemap 的明確位置。
| # 允許所有爬蟲抓取全站內容 User-agent: * Disallow: # 告訴爬蟲網站地圖在哪裡 Sitemap: https://www.example.com/sitemap.xml |
(注意:Disallow 後面留空,就代表什麼都不阻擋,即全站 Allow。)
範例二:測試站上線前,全站禁止抓取(正式環境請絕對避免使用!)
如果你正在建置新網站、進行大幅度改版,或是擁有一個專屬的內部測試網域(如 staging.example.com),請務必使用以下設定,避免未完成的內容、亂碼或假圖被 Google 索引到正式搜尋結果中。
| # 禁止所有爬蟲抓取網站上的任何東西 User-agent: * Disallow: / |
(注意:只有一個斜線 / 代表整個網站的「根目錄」及其以下所有內容。正式網站上線的那一刻,務必記得移除這個斜線!這是新手最常犯的致命錯誤。)
範例三:WordPress 網站標準設定(阻擋後台與系統目錄)
針對目前市佔率最高的 WordPress 架站系統,通常建議阻擋後台登入區域與包含隱私資訊的系統目錄,但必須放行前端視覺渲染所需的系統檔案(如:AJAX 處理程式)。
| User-agent: * Disallow: /wp-admin/ Disallow: /wp-includes/ Allow: /wp-admin/admin-ajax.php Sitemap: https://www.example.com/sitemap.xml |
範例四:大型電商網站(阻擋站內搜尋與複雜的篩選參數)
電商網站常會因為條件篩選(如價格區間、顏色分類、熱銷排序)產生俗稱的「分面導覽(Faceted Navigation)」問題。這會產生上萬個重複或內容極度相似的網址,嚴重消耗檢索預算,這時可以利用萬用字元阻擋特定參數。
| User-agent: * # 阻擋站內搜尋結果頁面 Disallow: /search/ Disallow: /?s= # 阻擋包含特定參數的網址(如排序與篩選) Disallow: /*?sort= Disallow: /*&filter= # 阻擋購物車與結帳這類無 SEO 價值的隱私流程 Disallow: /cart/ Disallow: /checkout/ Sitemap: https://www.example.com/sitemap.xml |
範例五:【AEO/GEO 策略】擁抱 AI 搜尋流量,並自主控管模型訓練爬蟲
這是一套符合目前 2026 最新 AI 趨勢的彈性配置。我們的策略邏輯是:積極允許傳統搜尋引擎(Googlebot)與 AI 即時搜尋引擎(ChatGPT-User)進入以獲取曝光;同時,針對專門用於訓練底層語言模型的爬蟲,網站管理員可依據自身的版權與資料政策,決定是否進行阻擋。以下範例提供給希望保留內容授權、暫不開放 AI 訓練抓取的用戶參考:
| # 1. 拒絕 OpenAI 訓練模型抓取 (保護版權) User-agent: GPTBot Disallow: / # 2. 拒絕 Google 模型訓練抓取 (完全不影響一般 Google 搜尋排名) User-agent: Google-Extended Disallow: / # 3. 拒絕 Anthropic (Claude) 訓練抓取 User-agent: Anthropic-ai Disallow: / # 4. 其他所有爬蟲 (包含 Googlebot, ChatGPT-User, PerplexityBot) 依循以下常規規則 User-agent: * Disallow: /wp-admin/ Allow: /wp-admin/admin-ajax.php Sitemap: https://www.example.com/sitemap.xml |
robots.txt 與 Meta Robots (noindex) 的差異釐清
這是一個極度重要、且實務上最多人(甚至部分SEO從業人員)會搞混的 SEO 觀念!
常見迷思:「只要我把網頁寫進 robots.txt 被封鎖 (Disallow) 了,這個網頁就絕對不會出現在 Google 搜尋結果中,對吧?」
答案是:很可惜,並沒有這麼理想!它還是極有可能會曝光在搜尋結果上。
要釐清這個問題,必須理解這兩者的管轄範圍完全不同:
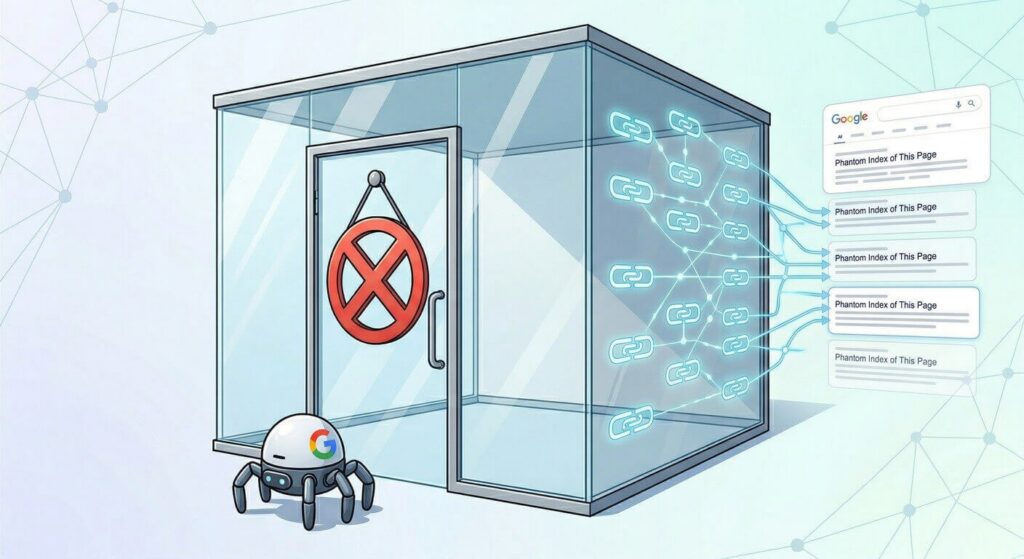
robots.txt (Disallow) 控制的是「檢索(Crawling)」
它就像是門口的警衛,告訴 Googlebot:「你不准進去這個房間看裡面的東西。」但是,如果網路上有其他網站的連結(Backlinks)指向了你這個私密房間,Google 雖然乖乖聽話沒進去看,但它透過別人的連結知道了這個網址的存在。這時,Google 還是可能會把它「索引(Index)」到搜尋結果中。在搜尋結果上,通常標題會顯示為該網址的路徑,或是出現「找不到這頁的說明(No information is available for this page)」的警告字樣,這反而顯得非常欲蓋彌彰。
Meta Robots (noindex) 控制的是「索引(Indexing)」
這是一段必須寫在該網頁本身 HTML <head> 區塊內的程式碼 <meta name=”robots” content=”noindex”>。它等於是網頁本身貼著一張字條,告訴 Googlebot:「歡迎你進來看,但你看完之後,絕對不要把我放到大眾搜尋結果清單上。」(註:如果你的機密檔案是 PDF 檔或圖片,因為沒有 HTML 標籤,你必須透過伺服器端的 X-Robots-Tag HTTP 標頭來設定 noindex。)
Google建議的解法:
假設你有一個極度機密的定價策略頁面 https://www.example.com/secret-pricing,你絕對不想在 Google 上被任何人搜到,你應該怎麼做?
- 先在目標頁面的 HTML 原始碼中加上 noindex 標籤。
- 確保你的 robots.txt 中「沒有」Disallow 該網頁!
這點非常反直覺!為什麼不 Disallow 呢?因為如果你在 robots.txt 中設定了 Disallow: /secret-pricing,Googlebot 就會被擋在門外。既然進不去,它就「永遠讀不到」裡面的 noindex 標籤。這反而會導致該頁面因為外部連結的關係,像幽靈一樣出現在搜尋結果中,所以要徹底消滅一個網址的索引,必須「放行讓它檢索,並讓它讀到 noindex」才行。
如何建立、提交與測試你的 robots.txt?
步驟1. 建立檔案📄
打開電腦裡的純文字編輯器(如 Windows 記事本、Notepad++ 或 VS Code),輸入上述建議的規則。存檔時,請確認兩個細節:
- 檔名全部小寫,必須精準命名為 robots.txt。
- 編碼格式強烈建議選擇 UTF-8(無 BOM)。如果使用了其他編碼,可能會產生看不見的亂碼字元,導致搜尋引擎解析失敗。
步驟2. 上傳至主機根目錄☁️
將檔案透過 FTP 軟體(如 FileZilla)或主機商的控制台(如 cPanel)上傳到網站的「根目錄(Root directory)」。上傳後,最簡單的驗證方式就是打開無痕瀏覽器,輸入 https://你的網域/robots.txt,確認可以正常看到文字內容且排版沒有跑位。
步驟3. 測試與驗證工具🔍
上傳完成後,你可以利用 Google Search Console (GSC) 進行確認。
- 雖然新版 GSC 介面中將舊版的即時測試工具移除了,但你仍可以在「設定 > 檢索統計資料」或是特定的「robots.txt 報告」中,查看 Google 上次讀取該檔案的時間狀態。
- 若要進行即時的單一網址語法測試,可以利用 GSC 上方的「網址審查(URL Inspection)」工具。輸入網址後,查看「網頁檢索」區塊,如果「是否允許檢索?」顯示為「否:遭到 robots.txt 封鎖」,就代表你的阻擋規則已成功生效。
- 進階技巧:對於資深的網站管理員,最準確的驗證方式是直接查看伺服器的日誌檔(Server Log Files),觀察特定 User-agent(如 GPTBot)嘗試存取特定路徑時,是否被伺服器回應了正確的阻擋狀態。
robots.txt 常見的 5 大錯誤與 Q&A 彙整
在輔導眾多企業網站的過程中,我們發現以下幾個 robots.txt 錯誤最常發生,甚至曾導致全站流量歸零的慘劇:
Q1:網址路徑的大小寫有差異嗎?
A1:有!非常嚴格!網址路徑是絕對區分大小寫的(Case-sensitive)。Disallow: /Admin/ 和 Disallow: /admin/ 代表兩個完全不同的目錄,建議在撰寫時再三確認網址的精確大小寫。
Q2:如果 Allow 和 Disallow 的規則衝突了怎麼辦?到底聽誰的?
A2:Googlebot 會採取「最長匹配路徑(Longest Match)」的優先原則。這意味著指令寫得越具體、字元越長的規則會勝出。
例如,你同時寫了:
Disallow: /folder/
Allow: /folder/page.html
因為 Allow 的路徑更長,所以 Googlebot 會允許抓取 page.html。
(小提醒:雖然 Google 遵循此規則,但並非所有小型的爬蟲機器人(如早期的 Bingbot 等)都具有相同的解析邏輯。實務上建議盡量避免撰寫過於複雜、互相衝突的規則,越簡單明確越安全。)
Q3:為什麼我的網站昨天就更新了 robots.txt 封鎖規則,今天 Google 還是去抓那些頁面?
A3:因為「快取機制」與「時間差」。Googlebot 為了節省資源,不會每分每秒都來讀取你的 robots.txt,它通常會將這個檔案快取約 24 小時。你可以到 Google Search Console 中手動要求重新抓取該檔案,或是耐心等待一到兩天讓設定自然生效。
Q4:為什麼我設定了 Disallow: wp-admin 卻完全沒有阻擋效果?
A4:這是新手最常犯的語法錯誤!在撰寫路徑時,目錄前面一定要加上斜線 /。
正確的寫法是 Disallow: /wp-admin/。如果少了前面的斜線,爬蟲會無法辨識這是一個相對於根目錄的路徑,導致該條指令直接失效。
Q5:跨網域(Cross-Domain)的網址可以寫進 robots.txt 來阻擋嗎?
A5:不行!除了 Sitemap 項目可以填寫絕對路徑(完整的 https://… 網址)之外,Allow 和 Disallow 的規則只能應用於相對路徑(以 / 開頭)。robots.txt 的管轄範圍僅限於它所存在的那個特定子網域(Subdomain)。它就像是自家門口的警衛,無法越權去管隔壁鄰居(其他網域)的事情。
robots.txt 看似只是一個不起眼的純文字檔,幾行簡單的程式碼,但它卻是實實在在掌握網站命脈的「流量總開關」。
從基礎的節省檢索預算(Crawl Budget)、防止測試環境外洩釀成災難,到如今 AI 世代面臨的版權資料保護與 GEO 搜尋流量佈局,定期檢視與嚴謹更新你的 robots.txt,已經是每一位網站管理員與 SEO 人員不可忽視的戰略性例行公事。
最後,必須再次叮嚀一個最核心的安全觀念:「robots.txt 防君子不防小人」。
它遵循的只是一種網路君子協議,正規的搜尋引擎與負責任的大廠 AI(如 Google, OpenAI, Anthropic)都會乖乖遵守;但如果是惡意的駭客爬蟲、內容農場的暴力抓取腳本,即使你寫了 Disallow: /,它們依然會視若無睹地強行闖入。
因此,如果是牽涉到會員個資、金流後台、機密定價等真正需要保護的頁面,請務必透過伺服器端的權限控管(如 .htaccess 阻擋、密碼保護登入、IP 防火牆限制)來處理,絕對不要天真地只依賴 robots.txt 來做資訊安全防護。
希望這篇文章能幫助你在傳統 SEO 與新興 AEO 雙軌並行的複雜時代,完美駕馭你的網站流量與爬蟲防禦策略:)🎉