
| 【💡 TL;DR / 文章核心摘要】 – 🎯 什麼是 Canonical:標準網址標記(rel=”canonical”)是用來告訴搜尋引擎眾多相似網頁中,哪一個才是「最原始」的標準網址。🚦 傳統 SEO 用途:過去它主要用於重複頁面排除,解決重複內容造成的權重分散與爬取預算浪費。 – 🤖 AI 時代的全新定位:進入 GEO(生成式引擎優化)與 AI 摘要 時代後,它是確立網站「資訊實體(Entity)源頭」的絕對關鍵。 – 🛡️ 版權護城河:當內容被大量轉載時,跨網域 Canonical 能提供保護原創版權參考,減少 AI 將官網誤認為抄襲者的可能。 – ⚠️ 實務避坑提醒:Canonical 無法直接拯救 AI 生成的低品質近似頁,且必須搭配結構化資料(Schema)的一致性,才能發揮最大防禦效用。 |
在輔導企業的過程中,我們常遇到客戶焦慮地問:「顧問,我們花了預算寫的超棒文章為什麼排名卡在第二頁?甚至搜尋結果跳出的竟是帶有 UTM 參數的奇怪網址,而非乾淨的官方主頁?」
這問題的元凶,高機率是「重複內容(Duplicate Content)」在作祟。
這就像圖書館有五本內容相同、僅封面不同(網址參數不同)的書。圖書館員(搜尋引擎)會非常困惑該推薦哪本;若五本書各自都有外部連結推薦,分數就會被平分。結果就是:權重被嚴重稀釋,沒有一本書能排上第一頁。
為解決「權重分散」與「爬取資源浪費」的痛點,進行有效的「重複頁面排除」便成為搶救排名的關鍵,而 SEO 業界長年依賴的終極武器正是——標準網址標記(Canonical Tag)。
然而,隨著 ChatGPT、Perplexity 與 Google AI 摘要崛起,許多人懷疑:「AI 語意理解這麼強,還需要手動標記標準網址嗎?」
答案是:需要,且比以往更加重要! 我們就以 SEO 顧問多年經驗的實戰視角,從傳統的重複頁面排除與網址管理,到目前幫助 AI 爬蟲如何管理頁面標準網址。這份指南大全將徹底解析 Canonical 的底層原理、高階策略與 GSC 報表解讀,幫你避開可能導致流量下滑的設定誤區。
什麼是 Canonical 標記?
簡單來說,Canonical 標記(標準網址標記)是放置於 HTML 網頁 <head> 區塊中的一段語法,其正式名稱為 rel=”canonical”。
用一句話解釋:它就是向搜尋引擎明確聲明,在一群內容高度相似或完全相同的網頁中,哪一個才是「唯一具代表性、應該被收錄並給予排名」的標準版本。
它的語法長這樣,看似非常簡單,卻在網站架構中極具威力:
<link rel=”canonical” href=”https://www.example.com/standard-page/” />
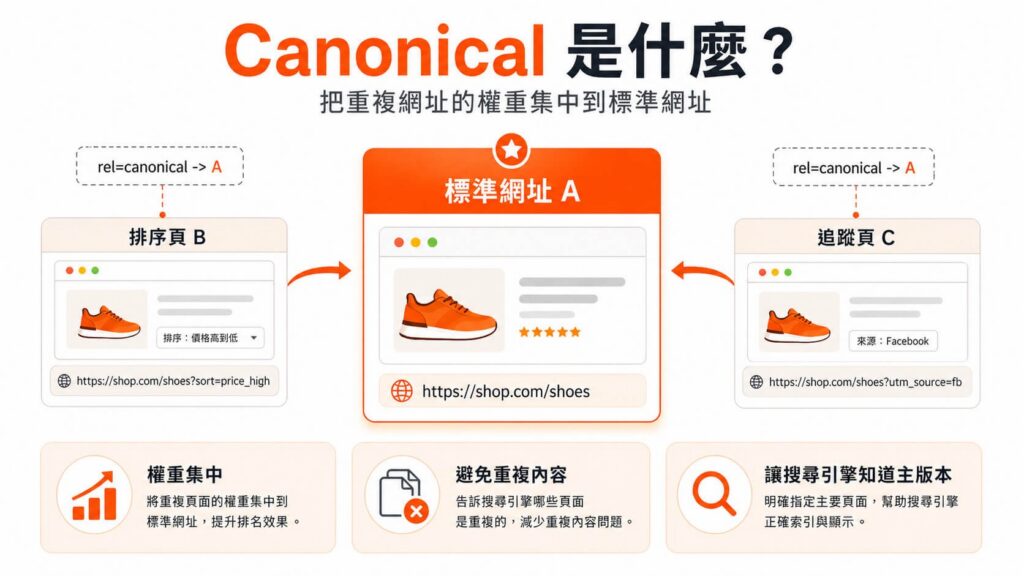
你可以把它想像成一種「選票集中機制」與「帳本統一作業」。
假設你有 A、B、C 三個內容幾乎一模一樣的網頁,但因為行銷活動或系統架構而擁有了不同的網址:
- A 頁面(你想排名的總部):乾淨的商品主頁 https://shop.com/shoes
- B 頁面(系統產生的分身):價格由高到低排序的頁面 https://shop.com/shoes?sort=price_high
- C 頁面(行銷產生的分身):Facebook 廣告追蹤網址 https://shop.com/shoes?utm_source=fb
如果你在 B 頁面和 C 頁面的網頁原始碼中,都加上指向 A 頁面的 Canonical 標記,這等於是 B 和 C 在主動告訴 Googlebot:「別管我們了,我們只是分身。所有的 SEO 權重、外部連結力量、點擊率累積與排名機會,請全部合併計算在 A(總部)的帳本上吧!」
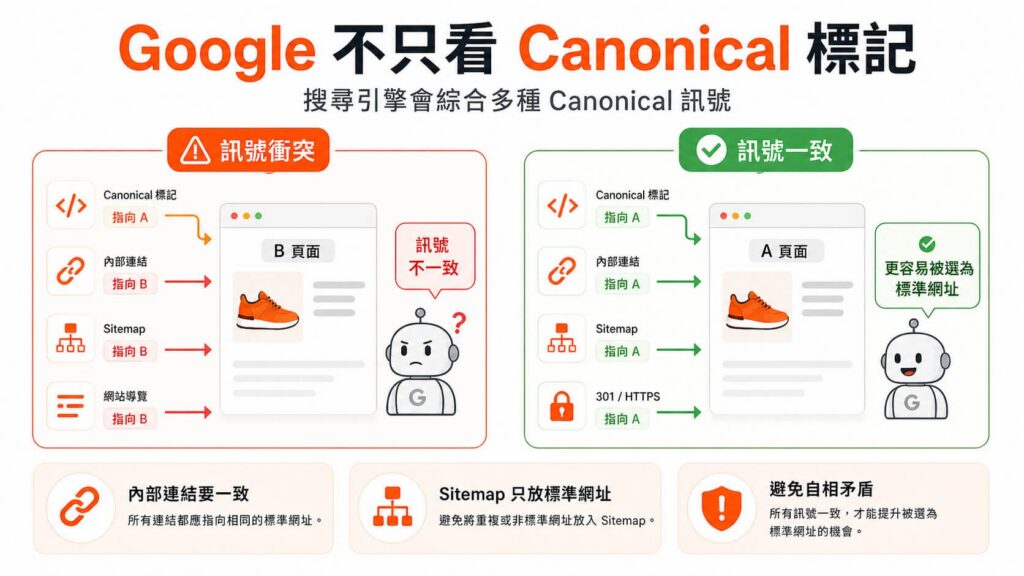
進階觀念:Google 不只看標記,更看整體訊號
請注意,標記 rel=canonical 只是其中一張選票。Google 演算法是透過『綜合訊號(Canonical Signals)』來決定的。如果你在 B 頁面加上了指向 A 的 Canonical,但在你的網站主選單、Sitemap.xml 以及所有的內部連結中,你卻死死地連向 B 頁面,這會產生嚴重的『訊號衝突』。Googlebot 會覺得:『你嘴巴上說 A 是標準網址,但身體卻誠實地一直推薦 B 呀?』最終,Google 會選擇忽略你的 Canonical 標記,自行把 B 認定為標準網址。因此,統一內部連結路徑,與 Canonical 標記同等重要。
觀點與實務操作建議分享
在實務部署上,有兩個極度容易翻車的細節必須留意:
- 務必使用「絕對路徑」,避免使用「相對路徑」:
在設定 href 屬性時,請務必寫出包含 https:// 與完整網域的「絕對路徑」。如果你貪圖方便只寫了相對路徑,在網站經歷 HTTP 轉 HTTPS、或是被其他內容農場惡意用 iframe 嵌入抓取時,容易產生無效的指向,甚至把你的 SEO 權重拱手送給惡意網域。
- ❌ 錯誤寫法(相對路徑): <link rel=”canonical” href=”/standard-page/” />
- ✅ 正確寫法(絕對路徑): <link rel=”canonical” href=”https://www.example.com/standard-page/” />
- 它是「強烈暗示」,而非「絕對指令」:
這點非常重要!Google 官方文件明確指出,Canonical 對搜尋引擎來說是一個「提示」。這意味著演算法會參考你的建議,但如果你設定的邏輯嚴重違反常理(例如:你把一篇講「蘋果手機規格」的文章,Canonical 指向首頁或是一篇講「香蕉營養」的頁面),Google 演算法會認為你可能設定錯誤、甚至在操縱排名,進而直接忽略你的標記,並自行挑選它認為最合適的網址。
為什麼 AI 時代更需要 Canonical?
在傳統的 SEO 戰場中,我們使用 Canonical 主要是為了解決內部架構問題,避免「關鍵字自相殘殺」以及「浪費爬取預算(Crawl Budget)」。如果 Googlebot 每天把寶貴的伺服器抓取額度,都花在爬取成千上萬個無意義的參數頁面上,你最新發布的部落格文章就永遠等不到被收錄的那一天。
但在 2026 年以後的 AI 搜尋時代,Canonical 被賦予了更高維度的戰略意義。在 Google AI Overviews / AI Mode 仍沿用傳統 Google Search 基礎規範的前提下,乾淨的索引、清楚的標準頁、可顯示 snippet 的內容,是網站被理解與引用的基礎。Canonical 不應被視為 AI 引用的直接排名因素,而是管理頁面標準網址與索引訊號一致性的基礎建設。
AI 怎麼決定誰是真正的原創來源?
無論是生成式引擎優化(GEO)還是解答引擎優化(AEO),AI 底層模型(如 GPT、Claude)在爬取網路資料,並透過技術為使用者產出即時答案時,它們最看重的核心指標是「資訊的明確性」與「源頭的權威度」。
當 OpenAI 的 OAI-SearchBot、GPTBot 爬蟲或其他 AI 爬蟲來到你的網站時,它們的運作方式與傳統的網頁排名不同,它們是在建構一個龐大的「知識圖譜」。如果它看到同一篇產業研究報告,同時散落在你網站的五個不同網址中,它的語意神經網路會產生認知混亂。
它無法確定哪一個網址才是這項資訊的「真正權威源頭」。確保資訊源頭的單一性,並將所有社群網路上的分享、各大論壇的外部連結訊號,全部集中在一個「標準目標頁面」上,是將你的網站列為「權威參考來源(Citations)」的關鍵。
💡 小提醒:OpenAI 官方資料並沒有明說 rel=”canonical” 是引用或權威判斷因子,但有鑒於其爬蟲原理有一定的相似與判斷之處,加上像是AI 摘要/AI 模式是採用Google自家系統,故一就可以作為提供判斷標準網址的依據。
Google AI 摘要 (AI Overviews) 會看 Canonical 嗎?
許多行銷人員有一種誤解,認為 AI 摘要(AI Overviews)是 Google 開發的另一套完全獨立的搜尋系統,可以不用管傳統的 SEO 技術規範。
事實上,Google 搜尋團隊的核心人物曾多次在公開場合暗示,AI 摘要的生成機制,高度依賴 Google 現有的核心搜尋索引資料。
如果你的網站因為長期缺乏 Canonical 的良好管理,導致 Google 的索引庫中塞滿了雜亂、重複、帶有大量追蹤參數的低品質網址,Google 系統會降低對你整個網站架構的信任分數。
請記住一個鐵律:一個乾淨、標準化、沒有重複內容的索引庫,是觸發 AI 摘要引用的先決條件。如果連傳統的 Googlebot 都不知道你網站裡哪一頁才是真正的主打頁面,AI 摘要將你的內容推薦給廣大用戶時也有有所顧慮。
AI SEO/GEO 時代該怎麼設定 Canonical?
在充分理解了底層運作觀念後,我們來看看在內容被大量散播、甚至 AI 生成內容氾濫的今天,該如何正確部署 Canonical。
文章發到多個平台,怎麼保護原創版權?
現在許多 B2B 企業與消費性品牌,會將自家部落格精心撰寫的文章,同步發布到 Medium、Vocus(方格子)、Midium、LinkedIn、或是透過公關新聞稿發布至各大科技媒體,以獲取更廣泛的同溫層外曝光。
可能發生的情境:
AI 爬蟲在抓取與評估內容時,往往會賦予大型權威媒體較高的信任權重。如果你把官網首發的獨家文章,一字不漏地貼到 Medium 上。幾天後你會發現,在使用者輸入關鍵字搜尋,或是詢問 AI 時,排在最前面、被 AI 引用的居然是 Medium 的網址。而你辛辛苦苦經營的官網,反而被演算法視為「抄襲者」或「重複內容」而遭到隱藏。
建議防禦策略:跨網域標準網址(Cross-domain Canonical)
很多人不知道,Canonical 標記是不受限於單一網域的!在與外部媒體、公關新聞發布平台或聯播網合作時,建議在合約條款或技術規範中提出要求:對方發布的該篇文章頁面,必須在 HTML 的 <head> 區塊中,加上指向你官網原文連結的 Canonical 標記。
透過這個設定,你就能打造雙贏局面:既能同時享有大媒體平台帶來的首波曝光與社群擴散流量,又能確保 AI 模型與傳統搜尋引擎明確知道:「這篇文章的真正原創主人與所有的 SEO 歷史權重歸屬,都屬於我的官方網站。」
【實戰交涉策略:如果對方不願配合怎麼辦?】
實務上,許多大型媒體或聯播網的 CMS 系統並不支援針對單篇文章自訂 Canonical,或者編輯部為了自身流量考量而拒絕配合。這時身為 SEO 顧問,我們有三個替代方案:
- 退而求其次,要求設定 noindex: 要求對方在網頁的 <head> 中加入 <meta name=”robots” content=”noindex”>,讓大媒體的流量純粹留在其站內與社群,不參與搜尋引擎的排名競爭。
- 採用「時間差發布策略」: 先在官方網站發布文章,並主動提交 GSC 請求索引,等待約 3 到 7 天,確認官網已經穩穩佔據搜尋結果第一頁且被 AI 爬蟲收錄後,再授權將文章發布到外部平台。透過發布時間的先後順序,也能暗示搜尋引擎誰才是真正的原創者。
- 置入連回官網的內部連結: 在授權轉載的文章內文中,自然地加入指向官網原文的連結。即使對方不加 Canonical,強而有力的反向連結也是 AI 與搜尋引擎判斷實體權威及資訊源頭的重要訊號。
💡小提醒:跨網域 Canonical 為「技術可行」,但若要做到轉載防禦,Google 現行建議更偏向請合作方使用 noindex,避免轉載頁與官網原文競爭索引。
AI 生成的農場文也可以用 Canonical 嗎?
這是近期我們在查核網站時,看到新手 SEO 操作者或工程師常見的設定誤區。
有些操作者會利用 ChatGPT 產生 100 篇內容只有 5% 到 10% 差異的「免洗農場文」。例如,為了做在地化搜尋(Local SEO),他們會自動生成「台北通水管推薦」、「台中通水管推薦」、「高雄通水管推薦」,但點進去一看,內文的段落、服務說明幾乎一模一樣,只替換了地名。然後,他們試圖在這些低品質的頁面上加上 Canonical,全部指向某一個服務主頁,企圖將這些長尾關鍵字的流量騙進主頁。
火柴盒顧問團隊提醒:
根據 Canonical 的官方定義,它是用來解決「因系統架構或網址參數產生的實質完全重複內容」。如果你刻意利用 AI 製造大量語意相近、但實質上缺乏獨特價值的低品質近似內容,這很容易觸發 Google 核心演算法中的「實用內容系統(Helpful Content System)」與 Spam 垃圾內容政策。
一旦被 Google 的機器學習模型判定為「濫用 AI 大量製造無價值內容」,整個網域都會面臨降權的風險。Canonical 並非低品質農場內容的避風港或遮羞布,建議把寶貴的資源花在撰寫真正能解答使用者痛點的優質原創內容上。
Google官方參考資料:Google 搜尋的生成式 AI 內容使用指南 (適用於網站)
網址莫名多出 srsltid 參數?電商最常遇到的重複問題
近期許多電商客戶跑來問:「顧問,我們的商品網址後面突然多了一長串 ?srsltid=… 的奇怪參數,而且還被 Google 索引並出現在自然搜尋結果中,這是網站中毒了嗎?」
別慌!這個 srsltid 參數其實是 Google 官方自己加的。當你有使用 Google Merchant Center (GMC) 並開啟了「自動標記(Auto-tagging)」功能時,只要使用者點擊了 Google 購物免費刊登的商品,網址就會自動帶上這個參數,用來幫助你在 Google Analytics 中追蹤成效。
但這引發了一個 SEO 問題:由於 Google 的系統判斷機制,爬蟲有時會把這些帶有 srsltid 參數的網址,當作全新的網頁抓取並放進自然搜尋結果中。這瞬間為電商網站製造了大量的重複內容,稀釋了原本商品主頁的權重。
火柴盒顧問團隊的建議:確實部署 Canonical 標記
這正是 Canonical 標記發揮作用的最佳時刻!Google 的搜尋倡導者 John Mueller 已經親自出面說明,這只是一個成效追蹤參數,遇到這種狀況,實務上的解法就是在所有商品頁面設定指向「乾淨原始網址」的 Canonical 標記。
請務必避免用 robots.txt 封鎖這個參數,這不僅會破壞你的成效追蹤,更會引發深層的技術問題:若使用 robots.txt 封鎖該參數,搜尋引擎將「無法爬取」該網頁,進而也「看不到」埋在裡面的 Canonical 標記。這會導致該網址仍可能被索引,且權重無法集中回主頁。只要你的 Canonical 設定正確(例如設定為 https://shop.com/shoes),Googlebot 就會清楚知道要把所有的權重歸還給乾淨的主頁,這場風波就不會對你的 SEO 排名造成實質影響。
只有 Canonical 不夠?進階的 AI 防禦技巧
在競爭激烈的 AI 時代,要做到滴水不漏的管理頁面標準網址,單靠在 <head> 塞入一行 Canonical 標記往往是不夠的,你還需要搭配以下兩個進階技巧:
- 精準阻擋 AI 擷取片段(Snippet 控制):
假設你有一個站內搜尋的動態結果頁(例如 https://shop.com/?search=running-shoes),你雖然很守規矩地加了 Canonical 指向正式的分類頁,但你更不希望 AI 爬蟲去把這個介面雜亂、充滿動態參數的搜尋結果頁拿去當作生成 AI 摘要的素材。
這時,除了 Canonical,你還應該在該動態頁面加上 <meta name=”robots” content=”noindex, nosnippet”> 標籤,或者在特定的 HTML 區塊使用 data-nosnippet 屬性。這樣能在原始碼層級,精準地阻擋 AI 擷取那些不具備代表性的文字區塊。
Google官方參考資料:Robots meta 標記、data-nosnippet 和 X-Robots-Tag 規格 - 確保 Schema 結構化資料高度一致:
這是一個進階、且容易被忽略的觀念!如果你的 A 頁面(分身)設定了 Canonical 指向 B 頁面(標準網址),請確保這兩個網頁原始碼中的 Schema 標記資訊高度一致。
Google官方參考資料:結構化資料通用指南
Canonical 跟 301 轉址差在哪裡?
這是一個重要、且實務操作上容易搞混的 SEO 觀念。到底什麼時候該請工程師設定 301 轉址,什麼時候又該在前端加上 Canonical?
301 轉址(Permanent Redirect) = 實體店面永久搬家,舊地址強迫改道。
當將舊文章 A 設定了 301 轉址到新文章 B,當使用者在瀏覽器點擊 A 網址的瞬間,伺服器會立刻攔截,並強制將畫面跳轉帶往 B 網址。使用者從頭到尾都看不到 A 頁面原本的長相。
- 建議適用情境: 舊款商品已經永久停產下架並需要合併流量至新一代商品、網站經歷大改版更換了全新的網域名稱(例如全站 http 強制跳轉 https)、刪除已經過時且不再維護的舊文章但想保留其 SEO 歷史權重。
Canonical 標記 = 相同內容的不同展示狀態,可正常瀏覽,但 SEO 積分統一計算。
當將帶有排序參數的網址 A 設定了 Canonical 到標準網址 B,當使用者點擊 A 網址時,畫面不會跳轉,使用者可以停留在 A 網頁繼續正常瀏覽與購物(例如依然能看到按價格由高到低排序的跑鞋清單)。只有搜尋引擎的爬蟲在背後看程式碼時才會知道:「原來 A 只是 B 的另一種展示模樣,把 A 在網路上收集到的所有 SEO 權重、點擊率與社群分享分數,全部打包算給 B 網址就好。」
- 建議適用情境: 各種數位廣告的追蹤參數(UTM 等)、電商網站的排序與條件篩選參數、分銷商推廣連結(Affiliate links)、同一個商品屬於多個分類路徑、必須保留網址供使用者正常點擊瀏覽,但內容實質完全相同的情境。
怎麼檢查 Google 到底選了哪個網址?
程式碼請工程師加上去了,然後呢?我們的工作還沒結束。你怎麼知道 Googlebot 有沒有採納你的建議?
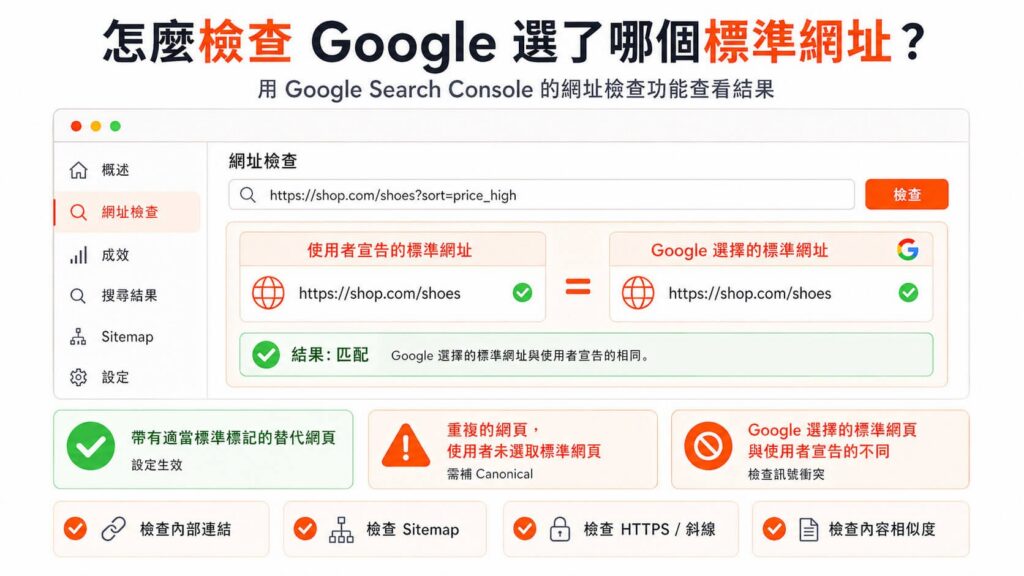
檢驗工具:Google Search Console (GSC) 的「網址檢查」功能
請登入你的 GSC 後台,將你剛剛設定好 Canonical 的「分身網址(非標準網址)」輸入到畫面頂部的搜尋列進行檢測。等待系統讀取後,打開下方的「網頁索引狀態」下拉區塊,你會看到兩個關鍵欄位:
- 使用者宣告的標準網址: 這裡顯示的是,你在該網頁 HTML 程式碼裡面自己手動寫的 Canonical 網址。
- Google 選擇的標準網址: 這裡是重點!這裡顯示的是 Google 演算法綜合評估了網頁內容、外部連結、Sitemap 等所有訊號後,最終評估判斷後挑選的「標準網址」。
如果這兩者顯示的網址一模一樣,恭喜你,你的設定已順利生效!
但如果你在 GSC 左側的「網頁(索引建立狀態)」大報表中,看到以下幾種常見狀態,請仔細閱讀我們的解讀:
- 🔴 提示狀態:重複的網頁,使用者未選取標準網頁
- 這是一個警訊!Google 已經在你的網站中發現了大量的重複內容,而且你並未設定任何 Canonical 標記來指引方向。Google 爬蟲現在正在自行猜測,這會消耗你的爬取預算,並可能導致網頁排名互相競爭。建議立刻找出這些網址並補上標記。
- 🔴 提示狀態:重複網頁;Google 選擇的標準網頁與使用者宣告的不同
- 這代表 Google 並未採納你的設定。你雖然寫了 Canonical,但 Google 判斷設定有誤。最常見的原因是:你把內容差異過大的 A 頁面指向了 B 頁面;或者,雖然你指定了 B 是標準網址,但全網卻有大量高權重外部連結連向了 A,導致 Google 演算法判定 A 才是較佳選擇。
當遇到這個狀況時,建議啟動三步驟除錯 SOP:
- 檢查內部連結:確保導覽列或舊文章沒有錯誤地指向不想排名的 A 頁面。
- 檢查 Sitemap.xml:請避免把非標準網址(A)放進 Sitemap 中,這會讓 Google 感到混亂。
- 檢查 HTTPS 與斜線版本:確保你指定的頁面 B 的標準網址 ,沒有漏掉結尾的斜線(Trailing Slash)或是誤寫成了 HTTP 版本。
- 檢查頁面內容相似度:實務上,若 A 頁面與 B 頁面內容差異過大(例如因缺貨導致頁面版型大幅改變),Google 會認定兩者並非重複內容而忽略標記。這是實務排錯時非常關鍵的檢查點。
- 🟢 安全狀態:帶有適當標準標記的替代網頁
- 這是非常好的消息!許多新手看到這個狀態沒有被收錄會很緊張。事實上,這代表 Google 成功讀取了你設定在分身頁面上的 Canonical 指令,並且正確地將這個分身排除在搜尋引擎的索引之外,把權重都順利歸還給了你的標準主頁。看到這個狀態,你可以放心。
💬 Canonical實戰常見問題彙整
在輔導大型跨國電商與新聞媒體網站過程中,我們發現以下幾個 Canonical 錯誤最常發生。請將這些 QA 視為網站上線前的必備查核清單:
Q1:不同語言的網頁 (Hreflang),Canonical 該怎麼設定?
A1: 這是跨國 SEO 操作中常見的設定誤區!不同語系(例如繁體中文版頁面與英文版頁面),對 Google 來說在語意上並不屬於重複內容。
實務上的標準做法是:採用「自我引用(Self-referencing)」。 繁中版網頁的 Canonical 應該指向繁中版自己;英文版網頁的 Canonical 應該指向英文版自己。接著再利用 <link rel=”alternate” hreflang=”…”> 標籤來告訴搜尋引擎它們的語言對應關係。
請務必避免: 千萬不要因為你覺得「這兩篇文章的意思一模一樣」,就把英文版的 Canonical 跨語系指向了繁中版主頁!一旦你這麼做,你的英文版網站可能會面臨無法被搜尋引擎收錄的風險。
Q2:如果網站是用 Vue 或 React 寫的 (SPA / JS 渲染),會影響 Canonical 嗎?
A2: 確實會有風險!Google 的開發者關係工程師曾多次提醒關於「兩階段渲染」的風險。
Googlebot 抵達網站時,會先快速抓取伺服器吐出的「初始 HTML 原始碼」。如果在初始 HTML 中沒有 Canonical,直到爬蟲進入排隊等待、執行完 JavaScript 後才動態塞入 Canonical 標記,可能會造成問題。Google 演算法若收到前後矛盾的衝突訊號,通常會導致該 Canonical 標記失效。
攸關 SEO 的關鍵 Meta 標記(包含 Title, Description, Canonical),請務必與前端工程師討論,透過 SSR(伺服器端渲染)或 SSG(靜態網站生成),將其直接寫入初始的 HTML 回應內容中。
Google官方參考資料:瞭解 JavaScript 搜尋引擎最佳化 (SEO) 基礎知識
Q3:測試站 (Staging Site) 內容跟正式站一樣,可以用 Canonical 把測試站指向正式站嗎?
A3: 實務上並不建議這麼做!測試站的標準防護做法是從根源阻擋檢索與訪問。
測試站最安全的做法是加登入驗證、HTTP authentication 或限制公開存取;若要用 noindex,需確保 Googlebot 能抓取頁面並讀到 noindex。robots.txt 可作為輔助阻擋爬取,但不應被視為阻止測試站 URL 出現在搜尋結果的唯一手段。
延伸閱讀:robots.txt 是什麼?AI 時代一樣有用,從 SEO 到AI 爬蟲的教學指南
如果你只用 Canonical 來處理,測試站的網址依然會被爬蟲無限制地檢索抓取。由於系統的延遲判斷,測試站的網址甚至有可能短暫出現在 Google 的搜尋結果中,讓真實的使用者點進一個充滿測試內容的 Bug 環境,這對品牌形象會產生負面影響。
Q4:HTTP 與 HTTPS,或是 WWW 與非 WWW 之間,只用 Canonical 統一就夠了嗎?
A4: 雖然 Canonical 在技術上確實可以解決不同協定造成的重複頁面問題,但建議優先使用伺服器層級的全站 301 轉址。
你應該在主機設定檔中,將所有的 HTTP 請求強制 301 永久跳轉到 HTTPS 安全協定,並將非 WWW 的網域強制轉到有 WWW 的主網域。在確實完成 301 轉址後,再於每個最終的標準頁面上,加上「自我引用(Self-referencing)」的 Canonical 標記作為第二道防線。這種「301 轉址 + 自我引用 Canonical」的組合,是實務上最穩健的架構。
Q5:電商分類的分頁 (如第一頁、第二頁),Canonical 該全部指向第一頁嗎?
A5: 不建議這麼做!這是一個流傳已久的過時錯誤觀念! 分頁並不屬於重複內容。分類列表中的第 2 頁展示的商品或文章,與第 1 頁展示的內容是完全不同、各自獨立的。
建議的設定做法是:第 2 頁的 Canonical 標記,應該老實地指向第 2 頁自己的網址。
如果你把第 2 頁、第 3 頁的 Canonical 全部指向了第 1 頁,你等於是在跟 Google 表示:「第 2 頁以後的內容較不重要,請忽略它們。」這將導致嚴重的收錄問題——放在第 2 頁之後的優質商品、長尾文章,可能會無法順利被爬蟲發現與收錄!
Google官方參考資料:分頁、漸進式載入網頁模式,以及對 Google 搜尋的影響
為你的網站建立清晰、權威的「數位戶口名簿」
最後,再次叮嚀一個核心觀念: 「Canonical 是一個非常實用的指引,但它並非用來隱藏網站架構缺陷、或是美化垃圾內容的魔法。」
它能優雅地解決系統參數、動態網址結構產生的技術性重複網址問題;但它無法單獨挽救薄弱、缺乏原創性、或是用 AI 粗製濫造的低品質內容。
在資訊全面爆炸、各式各樣的 AI 爬蟲無孔不入的全新時代,整個網際網路的架構就像是一座龐大且深不見底的迷宮圖書館。
你的 robots.txt 決定了誰有資格走進你網站的大門,而 Canonical 標記,則是在茫茫書海中,告知誰才是這裡真正值得被 AI 系統與搜尋引擎推薦給全世界的「目標頁面」。
希望這篇實戰指南,能幫助你在傳統 SEO 穩紮穩打,同時在新興 AEO 雙軌並行的複雜時代中,妥善駕馭你的網站架構。讓每一次的爬蟲造訪都充滿效率,讓 AI 系統毫無懸念地選擇你,成為使用者提問時的最終標準答案!
現在就打開你的 Google Search Console,進入「網頁索引建立」報表,檢查是否有大量未設定標準網址的重複頁面吧! :)🎉
火柴盒科技讓品牌在 SEO 與 AI Search 時代脫穎而出!
想在 SEO 與 GEO(AI Search)的浪潮中穩佔先機,兼顧流量成長與 AI 引用能見度嗎?
火柴盒科技 🥢🔥 擁有深厚的實戰底氣:
- 經驗豐富: 累積超過 300 個 SEO 專案成功經驗。
- 產業廣泛: 合作品牌橫跨電商、內容媒體、B2B、教育等多元領域。
- 技術領先: 緊跟 AI 搜尋趨勢,提供經實證有效的 SEO 與 AI 搜尋優化(GEO) 解決方案。
我們不只是優化關鍵字,更是在優化品牌語意架構,我們深知如何透過精準的內容佈,讓你的專業在 AI 時代被看得見、被讀得懂。別讓你的優質內容淹沒在數據碎片中,歡迎與我們聯繫諮詢,讓我們為品牌燃起亮光,帶動跨世代的搜尋成長!